
juuuding
[CS231n] Lecture 5. Convolutional Neural Networks 본문
지난 시간 Neural Networks에 대해 알아보았고 이제 Convolutional Neural Networks를 학습할 것이다. 작동 방식을 학습하기 앞서 Convoltional Neural Networks의 역사에 대해 알아보자.
History
[Perceptron(~1957)]
Mark 1 Perceptron 기계는 퍼셉트론 알고리즘의 첫 실행. 이 기계는 20*20 photocells를 사용하는 카메라와 연결되어 있었고 400 pixel 이미지의 결과를 냈다. 픽셀 값은 1 또는 0으로만 표현이 되었고, 역전파에서 사용한 것과 비슷한 update rule이 사용되었지만 역전파의 원리를 적용하지는 않았다. 이것으로 알파벳을 인식할 수 있었다.

[Adaline/Madaline(~1960)]
linear layer을 multi layer percept neural network로 쌓기 시작했다. 하지만 여전히 역전파는 도입되지 않았다.
[First time back-prop became popular(1986)]
[Hinton and Salakhutdinov(2006)]
pretraining 단계에서 layer을 반복하여 훈련하면서 weight을 초기화한 후 hidden layer을 모두 정했으면 이것을 full neural network로 만든다. 그리고 이 neural network로 역전파 과정도 진행하고 fine-tuning도 진행한다.
[First strong results]
Context-Dependent Pre-trained Deep Neural Networks에서 처음으로 strong result를 가지게 되었고 이것은 speech recognition이 잘 작동되도록 만들었다. 같은 해에 그 다음으로 deep convolutional neural networks를 가지고 Imagenet classification을 진행하면서 strong result를 얻었다. 이후로 ConvNets은 계속 널리 사용되게 되었다.
[Hierarchical organization]
1950-1960년대에 Hubel & Wiesel이 고양이에 대한 실험으로 시각에 다른 종류의 자극을 주었을 때 뇌에서 발생하는 전기적 신호가 다름을 알아내었다. 뇌의 시각 피질의 영역마다 각각 대응되는 공간이 있다는 것이다. 그러면서 뉴런이 hierarchical organization을 가진다는 것을 발견하였는데, 우선 빛의 방향과 같은 정보를 simple cells에서 받아들인 후 그것을 계층 구조로 연결하여 빛의 방향과 움직임에 반응하는 complex cells로 보낸다. 그리고 또 여기서 발생한 정보를 Hypercomplex cells로 보내면서 end point의 움직임에 반응(corner에 대한 아이디어)하도록 한다. 이와 같이 뉴런의 구조가 계층 구조로 이루어져 있어 간단한 cell과 복잡한 cell로 연결되어있다.
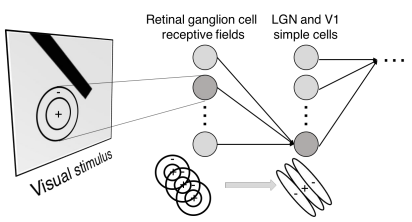
[Neocognition(1980)]
간단한 cell과 복잡한 cell이 샌드위치 구조로 번갈아 가며 layer을 구성하는 Neocognition이 나왔다.

[Gradient-based learning applied to document recognition(1998)]
CNN 학습에 역전파와 경사 기반 학습을 적용하였다. 이 당시까지는 아직 복잡한 데이터를 적용하지 못했지만, digit은 비교적 간단한 데이터이기 때문에 우체국에서 이를 활용하여 zip code recognition을 널리 사용하였다.

[ImageNet Classification with Convolutional Neural Networks(2012)]
위의 LeNet-5와 크게 달라보이지 않지만 여기서는 큰 데이터를 사용할 수 있게 되었다. 이것이 가능하게 된 데에는 병렬 처리가 가능해진 GPU의 역할도 크다.

[Fast-forward Today: ConvNets are everywhere]
이미지 분류, 비슷한 사진 매칭, 검색, 박스 형태로 물체 탐지, 박스 형태가 아닌 물체의 테두리를 따라 물체 감지도 가능해졌다. 이것은 자율 주행, 얼굴 인식, 비디오, 자세 인식, 게임, 의학, 은하계, 교통, 고래 인식, 항공 사진 인식, 사진을 보고 사진에 대한 설명, 예술 작품 만들기까지 적용할 수 있다.


Convolutional Neural Networks
앞에서 CNN의 역사에 대해 알아보았다. 지금부터는 CNN이 작동하는 방법에 대해 알아보겠다.
[Fully Connected Layer]
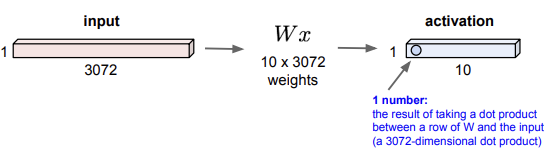
아래의 그림은 "fully connected layer"이다. 32x32x3의 크기를 가진 이미지를 3072x1로 펼쳐서 각각의 파라미터 값과 계산을 하면 그 결과는 actication가 된다. 만약 10개의 weights이 있었다면 결과는 총 10개의 뉴런으로 구성된 activation으로 나온다.

[Convolutional Layer]
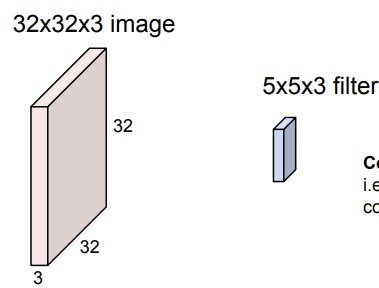
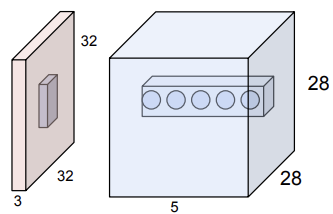
위와 달리 convolutional layer에서는 input image를 펴지 않고 32x32x3 이미지 구조를 유지한다. 그리고 선택한 필터와 함께 "Convolve"해주는 것이 convolutional layer이다. 즉, 공간적으로 필터를 이미지에 slide시키며 dot product를 진행하는 것이다. 아래의 그림에서도 볼 수 있다시피 input image와 filter의 depth는 항상 같아야 한다.
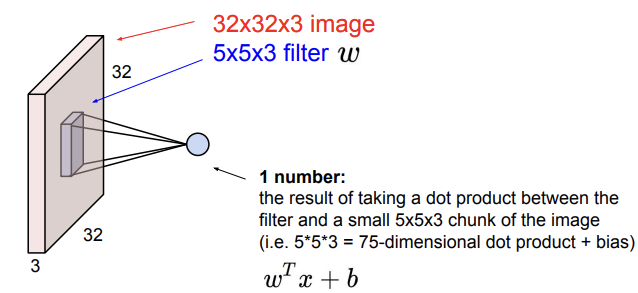
filter을 image에 slide시킬 때는 filter 크기의 image chunk에 filter을 겹치게 둔 후 filter의 값과 이미지의 값을 dot product 해주면 된다.
그러고 나면 내가 정한 설정 값들에 따라 output이 만들어지고 이 결과는 하나의 activation map이 된다. 이 output의 크기는 내가 slide 방식을 어떻게 정하느냐에 따라 달라진다.

convolutional layer에는 다수의 필터가 존재한다. 그렇기 때문에 위의 첫번째 필터가 image 전체 공간을 모두 지난 후 같은 input image에 또 다른 필터를 가지고 같은 동작을 수행하면 새로운 activation map이 생성된다.

만약 5x5 크기의 필터가 총 6개 존재한다면 결과로 6개의 activation maps를 얻을 것이다. 그리고 이 activation maps를 쌓아서 28x28x6의 크기를 가진 "new image"를 얻게 된다.
이러한 convolution layer 사이에 activation function을 넣고 layer들을 이어서 ConvNet을 만든다. 여기서 만들어진 output은 다음 layer의 input이 된다. 참고로 각각의 layer은 다수의 filters를 가지며, 각각의 filter는 하나의 activation map을 만들어낸다. 그리고 layer마다 몇개의 filters를 가지게 할지 구성하는 것은 가장 잘 작동하는 방식으로 구조를 선택하면 된다.


위 그림과 같이 CNN의 원리는 간단한 것에서 복잡한 것으로 향하는 아이디어에서 나왔다. 이러한 아이디어는 Hubel&Wiesel의 아이디어와 compatible하다.
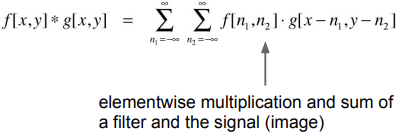
우리가 layer을 convolutional 하다고 부르는 이유는 이 layer이 두 signals의 convolution과 관련이 있기 때문이다.
input image는 아래와 같은 순서의 layer들을 지나며 여기서 발생한 모든 convolutional outputs는 연결시키고 이것을 final score function을 얻는데 사용한다.

[Spatial dimensions]
이제 filter가 input image를 slide 하는 spatial dimension이 어떻게 작동하는지 알아보자. 우선 예시로 7x7 input image, 3x3 filter라고 하자. filter을 image 위에 겹쳐서 각 원소에 대응하는 값들을 dot product 해준다.
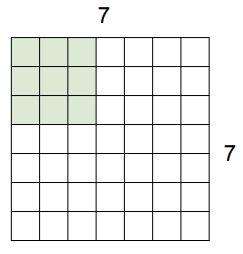
이 후 filter을 옆으로 slide한다. 그리고 똑같이 원소끼리 dot product를 진행한다.
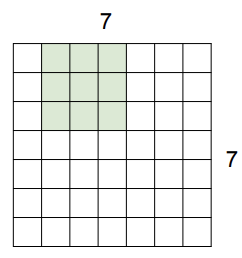
계속 똑같이 진행하다가 행 기준으로 마지막으로 겹치는 순간이 오면 멈춘다. 이때는 이러한 과정을 거쳐서 5x5 output이 만들어진다.
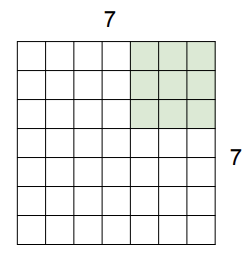
이제 위와는 다르게 filter을 2칸씩 slide 해보자.
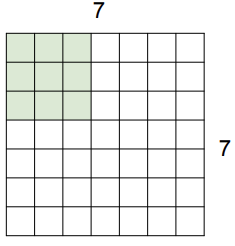


이렇게 두칸씩 slide하면 3x3 크기를 가진 output이 만들어 진다. 그리고 직접 3칸씩 slide해보면 딱 맞아 떨어지지 않는 것을 확인할 수 있다. 이런 경우는 진행하지 convolution을 하지 않는다.
아래의 공식을 사용하면 image와 filter의 크기, 그리고 stride(몇칸씩)의 값으로 output의 크기를 계산할 수 있다.
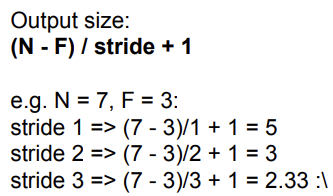
+ 실전에서는 zero pad the border을 흔히 사용한다. 이것을 사용하는 방법은 기존의 이미지의 끝에 0를 넣어 이미지의 크기를 늘려준 후, 하던대로 filter를 가지고 slide를 하면 된다. zero pad를 넣었을 때 output size를 계산해보면 output의 크기가 좀 더 커진다는 것을 알 수 있다. 이러한 작업을 해주는 이유는 이 전 input의 크기를 유지하기 위해서다. padding을 하지 않으면 output은 input의 크기보다 더 작은 크기로 나오는데, 이것을 방지하고자 padding을 해주는 것이다. 참고로 padding이 꼭 0일 필요는 없다.


일반적으로 흔히 CONV layer은 stride을 1로 하고, zero-padding을 (F-1)/2 정도로 해준다. F는 필터의 크기이다. 이렇게 zero-padding을 해주면 input의 크기가 유지되면서 결과가 나온다.

padding을 하지 않으면 input의 크기는 굉장히 빨리 줄어든다. 이러한 현상은 좋지 않고 작업이 잘 작동하지 않게 만든다.
input의 크기를 줄이지 않기 위해서 필터의 크기를 1x1로 만들어 줄 수 있다. 필터의 크기를 1x1로 하고 stride를 1로 하면 input 값과 같은 크기( depth 제외)의 결과 값이 나온다.

[The brain/neuron view of CONV Layer]
생물학적 뇌와 CONV Layer의 공통점은 "dot product"를 한다는 것이다. 하지만 생물학적 뇌에서 뉴런은 entire connectivity인 반면 CONV Layer에서는 local connectivity이다.

5개의 필터가 있으면 다음 output의 depth는 5가 되며, input volume에서 같은 영역을 보는 5개의 다른 neuron(output)이 존재할 것이다. 이 5개의 뉴런들은 input의 같은 영역을 보지만 그 안에서 서로 다른 것을 본다.
input image를 일자로 펼쳐 계산을 진행하는 fully connected layer을 떠올려 보자. 여기서는 각각의 뉴런이 stretched input과 연결되며, 이 뉴런들은 펼쳐진 full input volume을 볼 것이다.
이제 전체 CNN을 구성하는 나머자 layer인 pooling layer와 FC layer을 간단히 살펴보자.
[Pooling layer]
pooling layer는 이미지의 크기를 조절할 때 사용된다. pooling layer는 각 activation map 마다 독립적으로 작동한다. 이미지의 크기를 조절하지만 depth의 크기는 변경하지 않는다.

- MAX POOLING
아래는 POOLING 중 MAX POOLING에 대한 그림이다. 여기서는 이미지를 downsampling하기 위해 pooling을 적용한 것이며, dot product를 하기 전 각 영역마다 max 값을 취하여 input image의 크기를 조절한다. 아래의 예시처럼 대부분의 pooling에서는 영역이 겹치지 않게 slide를 한다.
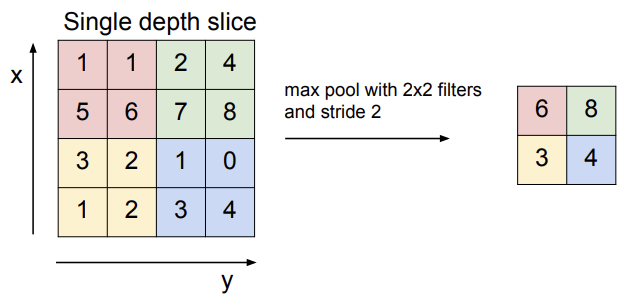
pooling은 downsampling을 하는 것이기 때문에 pooling layer에서는 보통 zero padding을 사용하지 않는다. pooling layer에서의 common setting은 (filter 크기 2, stride 2) or (filter 크기 3, stride 2)로 설정한다.
[Fully Connected Layer (FC layer)]
FC layer는 전체 input volume을 연결하는 뉴런을 포함한다. 그러기 위해서 FC에는 이전 layer에서 나온 output을 모두 펼친 후 convolutional map outputs를 모두 연결한다.
'인공지능 > cs231n' 카테고리의 다른 글
| [cs231n] 전체 정리 (0) | 2024.08.05 |
|---|---|
| [CS231n] Lecture 6. Training Neural Networks, Part 1 (0) | 2024.01.25 |
| [CS231n] Lecture 4. Backpropagation and Neural Network (0) | 2023.12.28 |
| [CS231n] Lecture 3. Loss Functions and Optimization (2) (1) | 2023.12.08 |
| [CS231n] Lecture 3. Loss Functions and Optimization (1) (0) | 2023.12.07 |


