
juuuding
[paper review] Learning From Imbalanced Data With Deep Density Hybrid Sampling 본문
[paper review] Learning From Imbalanced Data With Deep Density Hybrid Sampling
jiuuu 2024. 7. 18. 17:40
※ 혼자 읽고 정리한 글이라 틀린 내용이 있을 수 있습니다.
[Learning From Imbalanced Data With Deep Density Hybrid Sampling]
https://ieeexplore.ieee.org/document/9723474
Abstract
1. 문제
대부분의 경우 모델을 학습할 때 훈련 데이터 세트에서 클래스 간의 샘플 수가 불균형하게 분포되어 있어, 분류기가 다수 클래스에 편향되어 소수 클래스의 성능이 저하되는 문제가 있다. 이를 해결하기 위해 이 논문에서는 DDHS라는 방법을 도입하여 불균형 데이터 세트에서 분류 성능을 향상시키고자 한다.
2. 기존 방법의 문제
- minority 클래스나 majority 클래스에만 집중을 하고 두 클래스 간 관계는 고려하지 않는다.
- SMOTE(Synthetic Minority Oversampling Technique) 과 같은 기존 방법은 원래 특징 공간에서 유클리드 거리를 사용해 가장 가까운 이웃을 찾아 합성 샘플을 생성한다. 하지만 유클리드 거리는 고차원 공간에서 정확하지 않아 제대로 된 합성 샘플이 생성되지 않는다는 단점이 있다.
3. 제안된 해결법
이 논문에서는 데이터 불균형 문제에 대해 Deep Density Hybrid Sampling(DDHS)라는 새로운 방법을 제안한다.
* DDHS
- 임베딩 네트워크: 데이터 샘플을 low-dimensional separable latent space에 투영하여 클래스 근접성(proximity)를 유지하도록 학습한다.
- 밀도 기반 샘플링: 다수 클래스와 소수 클래스의 고품질 샘플을 선택하는 기준으로 density를 사용한다.
- feature-level approach: 선택된 소수 샘플에 "특징 수준 접근"으로 소수 클래스에 대한 다양하고 유효한 합성 샘플을 생성한다.
4. 실험 결과
광범위한 실험으로 DDHS가 유망하고 안정적인 결과를 제공함이 증명되었다. DDHS를 부스팅 기법과 결합했을 때, 여러 앙상블 방법과 비교하여 우수한 성능을 보인다.
이 논문에서 두 클래스 간의 관계를 어떻게 고려하는지, 저차원 분리가능 잠재 공간은 무엇인지, density로 고품질 샘플을 어떻게 선택하는지 궁금하다. 그리고 "특징 수준 접근"이 어떠한 방식으로 소수 클래스 합성 샘플을 만들 수 있는지에 대해 의문이 생겼다. 논문을 잘 읽어 보며 알아가보자.
💡 Introduction
1. 문제점
해결하고자 하는 문제는 불균형 클래스 분포를 포함하는 데이터 세트 처리다. 불균형 데이터 세트는 분류기가 다수 클래스에 편향되도록 만든다. 이러한 불균형 데이터 문제는 의료, 소매 등 다양한 응용 분야에서 문제 발생한다.
2. 불균형 데이터 문제에 대한 기존 방법들
① 랜덤 샘플링
- 오버샘플링: 소수 클래스로 데이터를 증식
-> 소수 클래스를 과적합하게 만들기 쉬움
- 언더샘플링: 다수 클래스의 데이터 개수를 줄임
-> 중요한 정보를 버릴 수 있음
② SMOTE (오버 샘플링)
- 오버 샘플링의 한 방법으로 k-nn을 이용하여 소수 클래스와 해당 클래스의 가장 가까운 데이터들로 선형 보간법을 사용하여, 소수 클래스에 대한 합성 샘플을 만드는 것이다.
-> k-nn에 사용되는 유클리드 거리가 고차원 공간에서 정확한 값을 내지 못하여, 고차원 데이터에서 SMOTE 방식을 사용하면 좋지 않은 결과를 발생시킴.
③ 하이브리드
- 오버샘플링과 언더샘플링의 문제를 완화시켜 두 방식을 혼합한 방법.
-> 임의의 데이터를 생성하거나 제거하여 원래 데이터 분포와 특성을 위반할 수 있음.
3. 제안된 해결책 - DDHS
논문에서는 불균형 데이터 문제를 해결하기 위해 Deep Density Hybrid Sampling이라는 새로운 방법을 제안한다.
DDHS는 아래의 방법들을 사용하여 불균형 데이터 문제를 해결한다.
① 임베딩 네트워크 학습
- 데이터 샘플을 "저차원 분리 가능 잠재 공간"에 투영하며, 투영 중에 클래스 근접성을 유지하는 것을 목표로 하고 클래스 내 및 클래스 간 개념을 사용하여 손실 함수를 설계한다.
② 밀도 기반 샘플 선택
- 다수 클래스와 소수 클래스의 고품질 샘플을 선택하는 기준으로 "density"를 사용한다.
③ 특징 수준 방법
- 선택된 소수 샘플에 특징 수준 방법을 적용하여 소수 클래스의 합성 샘플을 만든다. 이때 만들어진 합성 샘플은 소수 클래스의 특성을 그대로 유지하고, 생성된 샘플의 다양성은 증가한다.
아직까지는 임베딩 네트워크 학습 방법이 이해가 잘 가지 않는다. 여기서 말하는 밀도가 뭔지도 궁금하다. 제일 의문인 것은 기존 데이터의 특성을 유지하면서 어떻게 다양성을 증가시킬 수 있는지다..
4. 결과
- DDHS는 13 dataset에서 다른 고전 방법, sota 방법과 비교했을 때 유망하고 안정적인 결과를 보였다. 그리고 이 방법은 저차원, 고차원 dataset 모두에서 좋은 성능을 보여 주었다. DDHS는 데이터 수준의 알고리즘이고 이를 boosting 기술을 결합하여 DDHS-boosting 도 개발하였는데, 이것은 다른 앙상블 방법과 비교하였을 때 아주 좋은 결과가 나타났다.
💡 Related Work
불균형 데이터 문제를 다루는 방법에는 데이터 수준 방법, 알고리즘 수준 방법, 앙상블 방법, 딥러닝이 있다.
1. Data-Level Methods
데이터 수준 방법의 핵심 아이디어는 분류기가 다수 클래스에 편향되지 않도록 클래스 분포 균형을 맞추는 것이다. 이 방법은 어느 분류기에서나 통합이 된다는 장점이 있다.
(1)-1 오버 샘플링
- SMOTE: 오버 샘플링을 사용하는 방법 중 하나이다. 소수 클래스 샘플로부터 합성 데이터 샘플을 만들어낸다. 하지만 생성된 데이터의 다양성이 제한적이라는 단점이 있다. 이러한 다양성의 한계를 보완하고자 Liu and Hsieh가 MBS(model-based synthetic sampling)이라는 방법을 고안해냈다. 그리고 SMOTE는 앞서 보다시피 고차원 데이터에 취약하다는 단점이 있다.
* MBS: 특징 관계를 알아내기 위해 선형 회귀를 사용하고, 알아낸 특징 관계에 기반하여 합성 샘플을 만들어낸다.
(2) 언더 샘플링
- Tomek link: "겹치는 샘플"을 제거하는 언더 샘플링 방법 중 하나다. 여기서 겹친다는 것의 기준은 Tomek link로 정의되는데, 소수 샘플 xi와 다수 샘플 xj 사이에 더 가까운 다른 샘플이 없을 때 (xi, xj) 쌍은 Tomek link를 형성한다. 즉, xi와 xj가 두 클래스의 경계에 가장 가까울 때 xj가 "겹치는 샘플"이 되어 다수 샘플에서 xj를 제거한다.
내 생각으로는 데이터의 균형을 맞추기 위해 다수 클래스의 샘플을 제거하고 싶은데, 그 중 소수 샘플과 가장 비슷한 샘플을 없애고자 이 방법을 사용하는 것 같다. 그래야 분류기가 소수 클래스와 다수 클래스를 조금 더 깔끔하게 구별할 수 있으니까..
오버 샘플링 / 언더 샘플링 깔끔하게 나눠 쓰고 싶었는데 Tomek link 설명 때문인지 언더로 갔다가 다시 오버 샘플링으로 넘어간 듯하다..
(1)-2 오버 샘플링
- Borderline-SMOTE: 소수 샘플들은 모두 중요하지만, 그 샘플 중 경계(borderline)에 있는 샘플들은 잘못 분류가 될 가능성이 있기 때문에 달라야 한다. 그러므로 소수 데이터를 3가지 단계(safe, danger, noise)로 구별한다. 그리고 Borderline-SMOTE는 danger level에 속한 데이터로 합성 샘플을 만든다.
Borederline-SMOTE의 아이디어가 Tomek link와 비슷하다고 하는데.. 어떤 점에서 비슷하다고 하는 건지 잘 모르겠다. Borderline-SMOTE에서 말하는 경계가 Tomek link라는 건가??
- Safe-level-SMOTE: 각 소수 클래스는 safe score을 할당 받고, 다른 케이스들에 기반하여 합성 데이터 샘플이 만들어 진다. 그리고 이렇게 만들어진 합성 샘플은 safe area에 분배된다.
- NRAS: Noise reduction a priori synthetic. 노이즈 감소와 데이터 생성에 집중된 방법이다. noise 단계에 있지 않은 소수 샘플로 합성 데이터를 만들어 노이즈로 인해 발생하는 문제를 피한다.
결론적으로 SMOTE가 사용된 방법은 소수 샘플들로 데이터를 합성하여 오버 샘플링을 한다는 특징이 있다.
(3) KDE
이와 같은 오버 샘플링 방법은 기저 데이터 분포를 고려하지 않고 데이터 샘플을 생성한다. 그래서 이전의 많은 연구들은 estimated density function(추정 밀도 함수)에 따른 데이터 샘플을 만들자고 제안해왔다. 이 중 가장 인기 있는 방법은 KDE(Kernel density estimation)이다. KDE는 kernel homogeneous functions의 평균으로 density function을 추정하는 방법이다. 이것으로 소수 클래스에 대한 density 분포의 추정이 완료되면, 이를 사용하여 소수 클래스에 대한 새로운 샘플을 생성한다. 이와 같은 방법을 통해 기저 데이터 분포를 고려하여 새로운 샘플을 만들어 낼 수 있다.
Borderline, safe SMOTE, NRAS에 대해 완전히 이해되지 않는다.. 데이터의 3가지 단계가 잘 파악되지 않아서 그런 것 같다. 그냥 단순히 다른 클래스로 오분류될 확률이 있는 기준으로 경계선을 나눈 건가?
KDE에서 말하는 density가 뭔지 정확히 모르겠다. 데이터 분포 밀도를 의미하는 건가? 그리고 kernel homogeneous function이 무엇인지도 나중에 찾아보자.
2. Algorithm-Level Methods
알고리즘 수준 방법에서는 오분류 비용을 이용하여 분류기가 소수 클래스에 더 많은 중요성을 두도록 해서 불균형 데이터 문제를 해결한다.
(1) 비용 민감 학습
소수 클래스를 다수 클래스로 잘못 예측 분류했을 때 더 많은 비용(다수를 소수로 오분류 했을 때보다)을 계산한다. 이 비용을 분류 알고리즘이 모델 훈련하는 동안 사용하여 데이터 불균형 문제를 해결한다. 다수 클래스 데이터가 더 많기 때문에 데이터를 분류할 때 다수 클래스로 분류를 할 확률이 훨씬 높은데, 이러한 오분류를 막기 위해 위와 같은 오분류 비용을 사용하는 것이다.
(2) 비용 민감 부스팅 알고리즘
비용 민감 학습과 AdaBoost를 통합시켜 소수 클래스에 대한 성능을 향상시킴.
(3) sampling, threshold-moving, soft-ensemble
위 3가지 방법을 합쳐서 비용 민감 신경망을 만들어냄. threshold-moving과 soft-ensemble은 비용 민감 신경망과 합쳐졌을 때 좋은 결과를 보임.
(4) CMTNN(complementary neural network) with SMOTE
언더 샘플링과 오버 샘플링 기술을 합친 것. CMTNN은 Truth NN, Falsity NN이라 불리는 상호보완적 피드포워드 신경망 쌍을 이용하여 잘못 분류된 데이터 샘플을 감지하고 제거한다.
3. Ensemble Methods
앙상블 방법은 다수의 분류기를 사용하여 예측 오류와 편향을 완화시킨다.
(1) SMOTEBagging (오버 샘플링)
SMOTE와 Bagging 기술을 합쳐 합성 샘플의 다양성을 증가시킨다. 여기서 마지막 분류는 majority vote를 기반으로 진행한다.
(2) SMOTEBoost (오버 샘플링)
SMOTE와 Boosting 알고리즘을 합친 방법이다. 부스팅 반복동안 소수 클래스에서 합성 샘플을 만들며 점점 성능을 향상시킨다. 성능을 향상시키는 방법은 새로운 weak 분류기가 오분류된 샘플의 가중치를 증가시켜 다음 weak 분류기가 오분류된 샘플을 더 잘 학습하도록 만드는 것이다.
(3) RUSBoost (언더 샘플링)
훈련 시간을 줄이고 AdaBoost와 랜덤 언더 샘플링을 결합하여 성능을 향상시킨다.
(4) SPE (언더 샘플링)
Self-Paced Ensemble. 분류에 noise를 주는 데이터는 높은 hardness values를 주고, 이 값에 기반하여 주요 샘플들만 골라 이것으로만 학습을 진행한다. 즉 hardness 값이 작은 data은 분류를 혼동시키지 않는 명확한 data들(informative)이고, 이러한 data들만 남겨두고 나머지는 제거하여 훈련하는 것이다.
4. Deep Learning
딥러닝 기법은 DNN을 이용하여 특징 표현을 학습하고 동시에 분류 작업을 수행한다. CNN에서 불균형 데이터는 아주 해로운 결과를 초래하는 것이 밝혀졌고, 오버 샘플링 방식이 이 문제를 다루는데 지배적이라는 것을 알아냈다.
(1) transfer learning
전이 학습은 2단계로 훈련을 나눠서 진행하는데, 첫번째는 balanced dataset으로 모델을 사전 학습하는 것이고 두번째는 해당 라벨 분류에 맞추 미세 조정을 하는 것이다.
(2) CSLC
cost-effective semisupervised learning with crowd framework. 두가지 샘플링 전략 + cost-sensitive crowd labeling.
(3) AUC-ELM, SAUC-ELM
area under the curve(AUC) maximization + extreme learning machines (ELMs). 이진 분류에서의 불균형 데이터 문제를 다룬다.
(4) CoSen
cost-sensitive DNN. 소수 클래스와 다수 클래스의 특징 표현을 학습하고, 매개변수와 클래스 민감 비용을 최적화한다. 그렇기 때문에 알고리즘 수준 방법이라고 할 수 있다.
(5) NUS-1, NUS-2
소수 클래스와 겹치는 다수 샘플을 제거하는 신경망에 기반한 것이다. (언더 샘플링)
💡 Proposed Method
앞서 소개된 data-level 방식의 연구들은 다수 클래스 샘플과 소수 클래스 샘플에 균형을 잘 맞추지 못하고, 고차원 데이터셋에서 정확한 계산을 하지 못한다는 단점이 있다. 이러한 단점을 해결하기 위해 데이터 포인트들을 최적 저차원 표현에 투영하는 아이디어가 고안되었다.
투영을 통해 데이터 차원을 줄이면 spectral clustering이 더 효과적으로 작동하여 각 데이터포인트의 최적 이웃을 식별하고, 데이터의 본질적인 클러스터 구조를 파악하는 데 도움이 된다. 즉, 데이터의 중요한 패턴과 그룹을 더 잘 찾을 수 있을 거란 의미다. 더하여 저차원에서 쿼리 용와 개념 간의 의미론적 상관관계를 계산하면 더 정확한 결과를 얻을 수 있다.
* spectral clustering: 그래프 이론을 기반으로 하는 클러스터링 방법. 데이터 포인트 간의 유사성을 그래프로 나타내어 클러스터를 찾는 방법
[DDHS]
앞선 문제를 해결하기 위해 투영 방법을 이용한 DDHS를 제안한다. DDHS는 크게 3가지 아이디어를 적용한다.
① 학습 가능한 임베딩 네트워크
- 임베딩 네트워크는 모든 데이터 포인트의 클래스 근접성을 유지하며 저차원 분리 가능 잠재 공간으로 투영한다.
② density 사용
- 고품질의 데이터 샘플을 고르기 위해 density를 사용한다.
③ feature-level 오버 샘플링
- 소수 샘플에서 합성 샘플을 만들 때 feature-level 오버 샘플링을 사용한다. 그리고 만들어진 합성 샘플이 조건을 다 만족하는지 vertification step을 거친 후, 만들어진 샘플과 모든 소수 샘플을 합쳐 최종 minority set을 만든다. 소수 샘플들은 majority set에 사용된 density 기준을 만족시켜야 한다.
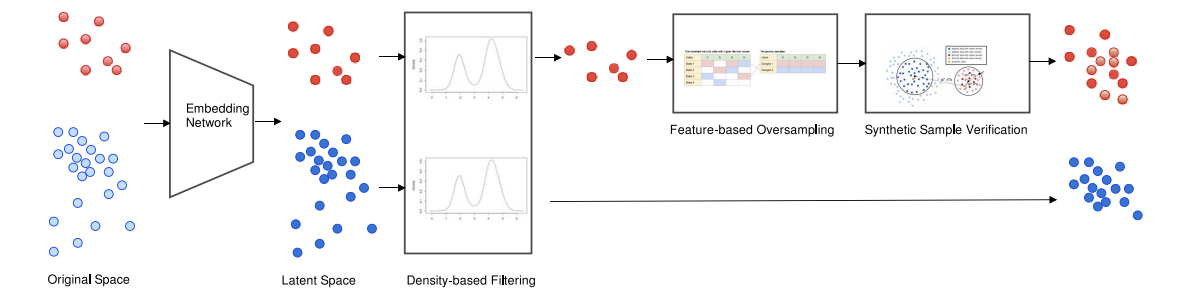
DDHS는 소수 클래스에 대한 오버 샘플링과 다수 클래스에 대한 언더 샘플링이 합쳐진 hybrid approach다.
1. Embedding Network
여기서는 확장된 오토인코더를 사용한다. 기존의 오토인코더는 인코더가 원래 데이터를 저차원 잠재 표현으로 변형하고 디코더가 해당 잠재 표현을 원래 데이터의 재구성에 연결한다. 이러한 과정에서 발생하는 재구성 손실을 최소화하면서 오토인코더를 최적화한다.

논문에서 사용할 확장된 오토인코더는 추가로 label y 정보를 이용하여 잠재 공간을 학습하고 클래스 근접성을 보존한다.

이 방법에서는 3가지 손실 함수(재구성 손실, 클래스 간 손실, 클래스 내 손실)를 사용한다.
① reconstruction loss(재구성 손실)
- 재구성 손실로 평균 제곱 오차(MSE)를 사용한다. 재구성 손실을 이용하면 데이터의 노이즈를 제거하며 잠재 공간으로부터 데이터 포인트를 재구성 할 수 있다.

* x_i : 오리지널 데이터 포인트
xhat_i : 재구성된 데이터 포인트
b : 배치 크기
② between-class loss(클래스 간 손실)
- 클래스 간 손실을 나타내기 위해서는 크로스 엔트로피 손실을 사용한다. 크로스 엔트로피는 틀린 클래스로 분류된 데이터 포인트에 더 많은 패널티를 준다. 따라서 데이터가 저차원 공간으로 투영되었을 때 다른 클래스로 잘못 분류되지 않도록 만든다.

* y : true label
yhat : prediction
③ within-class loss(클래스 내 손실)
- 클래스 내 손실을 나타내기 위해서는 center loss를 사용한다. center loss c_yi는 저차원 잠재 공간 안 yi 클래스의 중심을 나타낸다. 여기서는 데이터 포인트가 자신의 class center에 떨어질수록 더 많은 패널티를 준다. 이것은 저차원 공간으로 투영된 데이터가 해당 클래스의 중심에 모이도록 하는 효과가 있다.
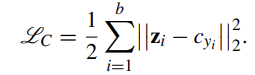
DDHS는 이 세가지 손실 함수를 결합하여 저차원 잠재 공간 표현을 학습한다. 그리고 이 잠재 공간이 분리 가능하도록 하여 투영된 데이터 포인트들이 명확히 분류되도록 한다. 이러한 방식으로 데이터 포인트들을 저차원 공간으로 투영하였기 때문에 DDHS는 고차원 공간에서 발생할 수 있는 문제를 완화시킬 수 있다.

SMOTE 에서 데이터를 오버 샘플링할 때 k-nn 방식을 사용하는데, 여기서 사용하는 유클리드 거리 공식이 고차원 데이터에서는 정확한 값을 계산하지 못한다고 했다. DDHS에서는 3가지 손실 함수가 결합된 오토인코더를 사용하여 최대한 클래스 근접성을 살리며 데이터를 저차원으로 투영하는 방식으로 위에서 말한 문제를 해결하는 것 같다.
2. Density-Based Filtering
임베딩 네트워크로 데이터 포인트를 저차원 잠재 공간으로 투영한 뒤, density를 사용하여 고품질의 데이터 포인트를 선택하고자한다. density는 어떤 데이터를 고품질 데이터라고 정의할까? 우선 low-density와 high-density가 의미하는 바를 알아보자.
- low-density data point: 다른 데이터 포인트들로부터 멀리 떨어진 곳에 있는 데이터. noise O.
- high-density data point: 다른 데이터 포인트들로부터 가까워, 클러스터를 대표할 수 있는 데이터.
따라서 high-density area를 고품질 데이터라고 정의한다.
이제 잠재 공간 포인트들의 density는 어떻게 계산되는지 알아보자. 여기서 density는 KDE( Kernel density estimation )를 사용하는데, KDE는 랜덤 변수의 확률 밀도 함수를 추정하기 위한 nonparametric 방식이다. 커널 함수에는 여러가지가 있지만, 데이터 포인트들을 center로 향하게 하며 강한 계산적인 이점이 있는 Gaussian KDE를 사용한다. Gaussian kernel function은 density의 부드러움에 영향을 주는 하이퍼파라미터 h를 가진다. bandwidth h는 m^(-1/[d+4])에 비례한다. 참고로 m은 샘플 수, d는 차원 수다.
이걸로 다수 클래스와 소수 클래스의 density를 계산한 후, density의 사분위 수(*quartile)로 데이터의 퀄리티를 평가한다. 다수 클래스냐 소수 클래스냐에 따라 평가 방식이 다른데 아래는 클래스별 평가 기준이다.
- majority class: density가 다수의 두번째 사분위수(Q2) 이상인 샘플을 유지
- minority class: density가 소수의 세번째 사분위수(Q3) 이상인 샘플을 유지. 다수보다 더 높은 기준을 가짐.
*quartile(사분위 수): 데이터를 네 개의 동일한 부분으로 나누는 통계적 지표. 사분위 수는 데이터를 네 부분으로 나눈 후 각 부분의 경계 값을 나타낸다. Q1, Q2, Q3 총 3개의 경계 값을 가진다.
- Q1: 데이터의 25% 지점. 데이터의 25%가 이 값보다 작고, 75%가 이 값보다 크다.
- Q2: 데이터의 50% 지점. 데이터의 절반이 이 값보다 작고, 절반이 이 값보다 크다.
- Q3: 데이터의 75% 지점. 데이터의 75%가 이 값보다 작고, 25%가 이 값보다 크다.
저차원으로 투영된 데이터 포인트들이 각 클래스 별로 모여 있을 것인데, 각 클래스마다 해당 퍼센트에 해당하는 샘플들만 고르는 것 같다. 예를 들어 소수 클래스에서는 중심을 기준으로 가까운 25% 샘플들을 골라내는 거 아닐까..
-> 논문의 바로 다음 내용에 똑같이 나와있었다!
그 결과 소수 샘플의 25%를 샘플 생성에 사용하고, 나머지 75%는 샘플 생성에는 사용하지 않되 분류 훈련에는 사용을 한다. 마찬가지로 다수 클래스에서는 샘플의 50%를 샘플 생성에 사용하고, 나머지 50%은 분류 훈련에만 사용한다.
즉 대표성이 뚜렷한 샘플들로만 새로운 샘플을 생성하겠다는 의미 같다.
3. Generation of Synthetic Samples
다양하고 유효한 합성 샘플을 만들기 위해서 feature-level 샘플링 기술이 사용된다. 이 방법은 예시로 설명하겠다.

우선 각 feature을 f_i라고 하고 feature은 총 4개로 구성되어 있고, KDE로 selected된 소수 샘플 데이터가 총 4개가 있다고 가정하자. 이 4가지 샘플을 가지고 새로운 샘플을 생성할 것이다. 우선 생성할 샘플의 첫번째 feature(f1)을 4가지 data의 f1 중에서 선택한다. 다음으로 f2도 4가지 data의 f2 중 하나를 선택하여 생성 샘플을 구성하도록 한다. 이러한 과정을 특징마다 반복하여 새로운 샘플을 만들어 낸다.
참고로 만들어진 샘플은 오직 demonstration 목적이기 때문에 이렇게 각 data에서 특징을 하나씩 들고와도 괜찮다.
이러한 방법을 사용하여 feature-level 샘플링이 가능하며, 더 다양한 합성 샘플을 만들 수 있게 되었다.
위 그림을 분석해본다면 sample1의 경우 첫번째 특징 / 세번째 특징은 data1으로부터 생성되었고, 두번째 특징은 data2로부터 4번째 특징은 data3으로부터 생성되었다고 할 수 있다. sample2의 경우 첫번째 특징은 data3, 두번째 특징은 data4, 세번째 특징은 data2, 네번째 특징은 data1으로부터 생성되었다.
4. Verification of Synthetic Samples
위의 방법대로 샘플을 만들고 나면 이 만들어진 샘플이 좋은 퀄리티를 가지는지에 대해 검증이 필요하다. 검증은 아까 합성 샘플을 만들기 위한 샘플을 고를 때 기준으로 사용한 것과 마찬가지로 density를 쓸 것이다. highest density는 클래스의 중심을 나타내고, lowest density는 클래스의 경계 지점을 나타낸다.
근데 여기서 클래스 density을 계산할 때 합성 샘플 + 기존 샘플을 쓰나? 아니면 그냥 기존 샘플만을 말하는 건가.. 헷갈린다. 느낌상 그냥 기존 샘플일 것 같다.
합성 샘플을 검증할 때는 두가지 기준이 사용된다. 우선 cM, cN을 majority 클래스와 monority 클래스의 중심이라고 하자. 그리고 rN을 선택된 minority 클래스의 반지름이라고 하자(cN과 클래스 경계 지점 사이 거리).
여기서 선택된(selected) 이라는 게 합성 샘플을 만들 때 선택된이라는 의미인가? 즉 사분위 수로 선택된 샘플들..??
기준 1) 합성 샘플이 cM보다 CN에 더 가까이 위치해 있나?

기준 2) 합성 샘플이 선택된 소수 클래스의 반지름 내부에 위치해 있나?


이러한 두가지 기준을 모두 만족할 수 있도록 합성 샘플을 훈련한다.
[Algorithm for DDHS]
- input: 훈련 데이터 (xi, yi) m쌍, oversampling 비율
- output: 새로운 데이터 셋(합성된 소수 클래스 샘플 + 소수 샘플 전체 + 저품질 데이터를 제외한 다수 샘플)
* 데이터 셋 생성 과정 : 임베딩 네트워크로 저차원 공간 학습 -> 학습된 공간으로 데이터 투영 -> 밀도 기반 필터링으로 소수 샘플의 고품질 데이터 선정 -> 다수 샘플의 저품질 데이터 삭제 -> 합성 샘플 생성 -> 합성 샘플 검증 -> 합성 샘플 + 소수 데이터 + 고품질 다수 데이터 = 새로운 데이터

[Time Complexity Analysis]
임베딩 네트워크 학습 과정이 시간 복잡도에 가장 중요한 영향을 미치기 때문에 중점을 두어 분석한다.
- 임베딩 네트워크 구조 (autoencoder + fully-connected layer)
① autoencoder
- encoder: 입력 데이터를 저차원 잠재 공간으로 투영. 3개의 계층으로 구성. 각 계층이 n1, n2, n3개의 뉴런으로 구성.
- decoder: 저차원 잠재 공간의 데이터를 원래의 고차원 공간으로 복원. 3개의 계층으로 구성. 인코더 계층 순서를 역으로 가짐
② fully-connected
- 뉴런 수는 nf로 n3와 같은 값을 가짐.
<시간 복잡도 분석>
순방향 전파, 역전파 인코더 계산 비용 : 2m(Dn1+n1n2+n2n3)
디코더와 fc-layer의 순방향 전파 계산 비용 : m(Dn1+n1n2+n2n3+n3nf)
O(2m(Dn1+n1n2+n2n3)+m(Dn1+n1n2+n2n3+n3nf))
각 epoch에서의 시간 복잡도는 O(mD)이므로, 전체 시간 복잡도는 O(emD)로 표현한다.
여기서 표현된 시간 복잡도가 잘 이해되지 않는다... 논문 다 읽은 후 조금만 더 생각해보자..
💡 Experiments
proposed method를 평가하기 위해 다른 12가지 방법과 비교해보았다.
1. Dataset
다음은 비교를 위한 실험에 사용된 dataset에 대한 테이블이다.

2. Comparison Methods
비교한 12가지 방법들은 SMOTE, Oversampling, Undersampling, Borderline SMOTE1, Boderline SMOTE2, Tomek link, SMOTE Tomek, Safe-level SMOTE, Gaussian SMOTE, NRAS oversampling, MBS + baseline method가 있다. 참고로 baseline은 어떠한 샘플링 기법, 전처리를 넣지 않은 방식이다. 제안된 방법이 data-level 알고리즘이기 때문에 비교 방법들도 data-level 방식들을 사용하였다.
3. Experimental Settings
(1)
데이터를 훈련/테스트 데이터로 나눌 때 10개의 다른 random seeds로 나누어 radom splitting으로 인한 효과를 완화하고, 데이터 샘플을 만들 때 또 10개의 다른 random seeds를 사용하여 샘플링 과정의 무작위성을 완화하였다.
따라서 총 100번의 실험을 하며 100개의 결과를 얻어, 이 결과의 평균을 내서 최종 평가 결과로 사용하였다.
샘플링 과정에 랜덤 씨드를 사용했다는 것이 잘 이해가 안간다.
(2)
분류기 부분에는 SVM과 logistic regression을 사용할 수 있다. 그 이유는 "추가적인 특징 조합" 또는 "커널 트릭"이 없는 선형 방법이라 생성된 데이터셋의 퀄리티를 평가하는데 적절했다. 그리고 이 두가지 분류기는 실제 환경에서 많이 사용되는 분류기이기 때문이다.
오버 샘플링과 언더 샘플링의 비율은 100%로 하였다.
- 오버 샘플링: 다수 샘플 수랑 같아지도록 소수 샘플 수를 증가시킴
- 언더 샘플링: 소수 샘플 수랑 같아지도록 다수 샘플 수를 감소시킴
(3)
SMOTE를 사용한 방법들에서는 k값을 모두 5로 설정하였다. (k-nn에 사용되는 k 값)
(4)
16차원을 기준으로 데이터셋을 저차원/고차원 데이터셋으로 분류한 뒤, 저차원/고차원 별로 각 grid search을 사용하여 잠재 공간의 차원을 결정하였다. 그 결과 고차원 데이터 셋은 잠재 공간 차원을 16으로, 저차원 데이터 셋은 잠재 공간을 2로 하는 게 가장 좋은 성능을 보였다.
저차원/고차원 데이터셋 별로 임베딩 네트워크의 인코더, 디코더의 3개 계층에는 각각 다른 input, output feature sizes를 사용하였다.
- 고차원 데이터셋(3계층 인코더) : (input size, 256), (256, 64), (64,16)
- 저차원 데이터셋(3계층 인코더) : (input size, 64), (64,16), (16,2)
디코더 네트워크의 크기는 인코더 네트워크의 반대 순서다.
- 고차원 데이터셋(3계층 디코더) : (16, 64), (64, 256), (256, input size)
- 저차원 데이터셋(3계층 디코더) : (2, 16), (16, 64), (64, input size)
(5)
활성화 함수
- 은닉 계층: ReLU
- 출력 계층: sigmoid
4. Evaluation Metric
평가 지표로 AUC와 AUPRC를 사용한다.
- AUC(Area Under Curve): ROC 곡선 아래의 면적을 나타내며, ROC 곡선의 모든 컷오프 포인트를 고려하여 모델의 전반적인 성능을 평가한다. ROC 곡선은 TPR, FPR를 각각 y축 x축으로 하여 두 비율을 나타낸 것이다.
* TPR: 실제 양성 중 모델이 양성으로 예측한 비율
* FPR: 실제 음성 중 모델이 양성으로 예측한 비율
- AUPRC(Area Under the Precision Recall Curve): 정밀도-재현율 곡선 아래의 면적을 나타낸다. 정밀도-재현율 곡선은 x축을 정밀도로 하고, y축을 재현율로 한 곡선이다. 클래스가 매우 불균형할 때 유용하다. 양성 클래스가 매우 적은 경우에도 성능을 정확히 평가 가능하다.
* 정밀도: 모델이 양성으로 예측한 사례 중 실제로 양성인 비율
* 재현율: 실제 양성 사례 중 모델이 양성으로 올바르게 예측한 비율
ROC 곡선에 대해 조금 더 알아보자.
5. Experimental Results
(1) linear SVM
대부분의 데이터셋에서 DDHS가 최고의 성능을 보인다. 특히 고차원 데이터셋(ex.Isolet)에서 아주 잘 작동하는 것을 확인할 수 있었다.

(2) logistic regression
모든 데이터셋에서 DDHS가 우수한 성능을 보였다.


(3) Wilcoxon rank-sum test
다음 평가 방식으로 DDHS가 다른 방식에 비해 상당한 성능 차이가 있는지 확인하기 위해 Wilcoxon rank-sum test를 사용하였다. 표에서 *쳐진 값을 가진 method들은 DDHS와 비교하였을 때 해당 데이터셋에서 큰 성능 차이가 없다는 것을 의미한다. 하지만 대부분의 경우 성능 차이가 꽤 났다는 결과를 확인할 수 있다.
(4) PCA
모델 훈련 과정에서 데이터 포인트를 시각화 하기 위해 PCA(주성분 분석)을 이용하여 데이터 포인트를 2차원 공간에 투영하였다. 모든 데이터셋의 범위를 PCA를 한 후 0~1 사이로 변형하였다. 다음 그림은 저차원 데이터셋(Letter)과 고차원 데이터셋(Optdigits, Sylva, Isolet)을 골라 결과를 시각화한 것이다.

저차원 데이터셋, 고차원 데이터셋 모두 DDHS의 임베딩 네트워크를 통해 데이터 분리가 잘된 것을 확인할 수 있다. 초기의 데이터는 다수, 소수 데이터가 잘 분리되어 있지 않은 상태였는데, 임베딩 네트워크를 거친 후 클래스별로 데이터가 잘 분리되었다. 이 결과를 통해 임베딩 네트워크에 사용한 3가지 손실 함수가 분리가능한 저차원 잠재 공간 학습을 아주 잘한 것이라고 결론지을 수 있다.
💡 Discussion
1. Loss Functions in Embedding Network
DDHS의 임베딩 네트워크에서는 3가지 손실함수를 이용하여 저차원 잠재 공간을 학습하였다. 손실 함수의 다른 조합을 실험하여 더 나은 결과가 있는지 알아보고자 한다. 추가적인 손실 함수로 LCE+LR, LC+LR, LCE+LC 3가지 조합을 DDHS의 LCE+LC+LR과 비교하였다.
* LCE: 크로스 엔트로피 손실, LC: 센터 손실, LR: 재구성 손실
이 실험을 통해 LCE+LC+LR 조합이 거의 모든 경우에서 가장 좋은 성능을 낸 것을 확인할 수 있었다. 그리고 특히 LCE는 제일 영향력이 큰 손실함수이며 다른 클래스 샘플들 간의 분리를 확실하게 해준다는 결론을 내었고, LC는 같은 클래스 샘플들을 중심으로 모아준다는 사실도 알 수 있었다. LR의 경우에는 라벨에 대한 정보를 포함하지 않기 때문에 성능에 가장 적은 영향을 미치지만, 그래도 모델의 성능을 향상시키는데 도움이 된다는 것도 확인하였다.


2. Ablation Study of Density-Based Filtering
DBF가 어떤 영향을 미치는지 확인하기 위해 DBF를 사용한 DDHS와 DBF를 사용하지 않은 DDHS의 성능을 비교하여 ablation study를 진행하였다. 아래의 표는 실험 결과인데 이 결과를 통해 DBF를 사용하여 데이터 샘플을 고르는 것이 성능 향상에 중요한 역할을 한다는 것을 알 수 있었다.

3. Comparison With PCA and Its Variants
DDHS는 차원 축소 과정을 거친다. 그래서 다른 차원 축소 방법들과 DDHS를 비교하는 실험을 진행하였다.
- PCA(unsupervised): 데이터 포인트를 저차원 공간으로 투영하여 데이터 변동 최대한 보존
- kernel PCA(unsupervised): 커널 트릭을 이용한 PCA 확장 버전으로, 데이터를 고차원 공간으로 매핑하여 비선형 패턴을 포착한 후 이 고차원 공간에서 PCA의 선형 연산을 통해 저차원 공간으로 축소.
- supervised PCA: PCA를 일반화하여 회귀, 분류와 같은 지도학습 문제를 해결. supervised인 만큼 레이블을 고려함. 입력 특징과 레이블 간의 의존성을 극대화하는 부분 공간을 찾아냄.
이 3가지 차원 축소 방법들과 DDHS를 비교한 결과는 다음과 같다.

PCA와 kernel PCA는 비지도 학습으로 레이블 정보를 사용하지 않기 때문에 차원 축소 후 저차원 공간에서 분류 작업이 항상 좋은 성능을 내지 못할 수 있고, supervised PCA는 레이블을 사용하지만 orthogonal projection matrix 선형 변환을 사용하기 때문에 제안된 방법보다 좋지 않다.
제안된 방법 DDHS는 레이블 정보를 사용하여 데이터 재구성을 통해 분리 가능한 공간을 학습하고 비선형 변환 과정을 수행하여 더 나은 결과를 도출한다.
4. Comparison of Kernel Density Estimation
DDHS에서는 KDE Kernel 함수로 Gaussian kernel을 사용한다. KDE Kernel 함수에 다른 함수들을 사용하여 이와 비교해보았다. 비교 함수로는 linear, tophat, exponential, Epanechnikov kernel 함수를 사용하였다.

(a)에서는 Gaussian kernel function이 다른 함수들보다 조금 더 나은 성능을 내는 것을 확인할 수 있었고, (b)에서는 다른 함수들에 비해 훨씬 나은 computational time이 나온다는 것을 확인했다.
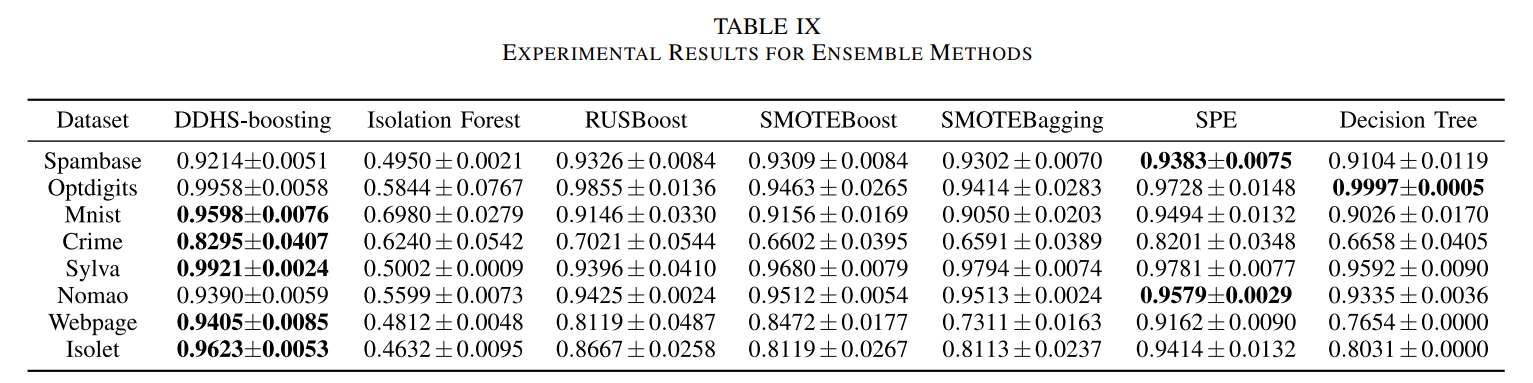
5. Ensemble Learning and Cost-Sensitive Methods
DDHS(데이터 수준 방법)와 AdaBoost 방법(알고리즘 수준 방)을 합쳐 DDHS-boosting이라는 앙상블 학습을 진행하였다. 비용 민감 결정 트리를 비교 방법으로 사용하여 가중치를 클래스의 frequency에 반비례하도록 조절하였다. 또, 50 features가 넘는 고차원 데이터를 실험에 사용하였다.
SPE도 overlapping classes와 아주 불균형한 분포에서 좋은 성능을 보이지만, DDHS도 좋은 성능을 보이며 boosting 프레임워크에 더 쉽게 적용될 수 있기에 더욱 향상된 성능을 발휘할 수 있다. 그렇기 때문에 DDHS-boosting이 다른 방법들보다 더 잘 작동할 것(특히 고차원 데이터셋에서)이라는 것을 알 수 있다.
* 부스팅 프레임워크: 여러 약한 분류기를 결합하여 강한 분류기를 만드는 앙상블 기법. 각 분류기는 이전 분류기의 오분류된 샘플에 더 높은 가중치를 부여하여 학습함.
6. Training Time and Prediction Time
DDHS를 큰 데이터셋에 적용하여 training, prediction 시간을 측정하였다. 컴퓨팅 환경은 "Intel Xeon CPU E5-2620 2.1 GHZ, 64-GB RAM, and an Nvidia GeForce 1080Ti (11 GB) GPU"을 사용하였다.
- training 시간: 288, 174, 179, 131, and 48 s (Isolet, mnist, spambase, optdigits, and crime 순서대로)
- prediction 시간: 0.016, 0.014, 0.013, 0.009, and 0.011 s ( Isolet, mnist, spambase, optdigits, and crime 순서대로 )
이 실험의 결과로 DDHS가 효율적이고 큰 데이터셋에 적용가능하다는 것을 알 수 있었다.
💡 Conclusion
- DDHS는 불균형 데이터 문제를 다루는 방법
- 제안된 방법은 데이터 수준 방법이고 딥러닝과 합쳐 발전시킴
딥러닝이 오토인코더 말하는 건가?
- 임베딩 네트워크: 저차원 공간 학습 -> 클래스 근접성 유지
- 밀도 기반 데이터 필터링, 특징 수준 방법 -> 잠재 공간에서 합성 샘플 생성
- 3가지 손실 함수 사용
- future work: DDHS를 time-series data에 적용할 수 있도록 확장시키기