
juuuding
[Advanced Learning Algorithms] Neural network training - Additional Neural Network Concepts 본문
[Advanced Learning Algorithms] Neural network training - Additional Neural Network Concepts
jiuuu 2023. 12. 6. 16:55Advanced Optimization
기존 gradient descent보다 더 나은 방법으로 빠르게 loss를 최소화할 수 있는 방법에 대해 알아보자.
[Gradient Descent]
아래는 간단하게 w에만 경사하강을 적용하는 식이다.

alpha 값이 적절하게 설정되어 있지 않을 때 발생할 수 있는 문제에 대해 두가지 경우로 나누어 알아보자.
① alpha(learning rate)이 작을 때
learning rate이 너무 작다면 경사하강을 진행할 때 한 방향으로 아주 조금씩 움직이며 최소 loss값에 천천히 가까워진다. 이때 learning rate 값을 적절하게 높여주면 조금 더 빨리 최소 loss 값에 가까워질 수 있다.
② alpha(learning rate)이 클 때
learning rate이 너무 크다면 경사하강을 진행할 때 한 방향으로 진행하지 않고 앞뒤로 왔다갔다 거리며 최소 loss 값에 도달하기 어렵게 될 수 있다. 이때는 learning rate를 조금 줄여주어야 하는데, 그렇게 하면 올바른 방향으로 경사하강이 진행되어 최소 loss 값에 도달할 수 있게 된다.
[Adam Algorithm Inutition]
이와 같이 경사 하강을 진행할 때 learning rate을 잘 조절해주어야 좀 더 효율적으로 loss 값을 최소화할 수 있다. 경사하강이 진행되는 방향에 따라 learning rate을 자동으로 조절해주는 알고리즘이 있는데, 이를 "adam algorithm"이라고 한다. adam은 Adaptive Moment estimation에서 따온 말이며, adam algorithm을 사용하면 alpha 값이 하나로 고정되어 있는 것이 아니라 자동으로 알맞게 조절된다.
[MNIST Adam]
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras import Dense
# model
model = Sequential([
Dense(units=25, activation='sigmoid'),
Dense(units=15, activation='sigmoid'),
Dense(units=10, activation='linear')
])
from tensorflow.keras.losses import SparseCategoricalCrossentropy
# compile
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3) ,loss=SparseCategoricalCrossentropy(from_logits=True))
# fit
model.fit(X,Y,epochs=100)
Adam algorithm을 사용하려면 compile시 optimizer option을 사용하면 된다. optimizer에는 위의 코드와 같이 작성하면 되고, learning rate의 기본 값을 설정해주어야 하므로 괄호 안에 default learning rate를 넣어주면 된다.
Additional Layer Types
[Dense Layer]
이때까지 사용한 dense layer은 이전 layer의 모든 unit에 대한 결과 값을 다음 layer가 보고 사용할 수 있었다.

[Convolutional Layer]
하지만 dense layer와는 달리 convolutional layer은 이전 layer의 일부 units에 대한 결과만을 다음 layer의 unit이 보고 사용할 수 있다. 예를 들어 아래에 hand-written 9가 input 으로 있다고 가정하자. 이 input을 입력받은 hidden layer을 구성하는데, 이 layer을 convolutional layer로 생성하면 첫번째 unit은 맨 왼쪽 상단 pixel만, 두번째 unit은 다음과 같은 2x2 사각형 모양 pixel만을 참고하도록 한다. 이런 식으로 layer의 units이 앞 layer 결과의 일부만 참고할 수 있도록 하는 것이 convolutional layer이다. 이처럼 convolutional layer을 적용하면 계산이 좀 더 빨라지고, trainaing data가 덜 필요하게 되며 overfitting이 발생할 확률이 줄어든다.

[Convolutional Neural Nerwork]
위에서 본 convolutional layer로 convolutional neural network를 생성할 수 있다. 예를 들어 심장병이나 심장의 컨디션을 확인하기 위한 EKG가 있다고 하자. 이 EKG를 세로로 세우고 이것을 layer의 input으로 사용하자.

dense layer에서는 다음 layer의 units이 모든 x에 접근이 가능하겠지만 convolutional layer을 사용하면 그렇지 않다. 한 예시로 convolutional layer을 만들어보자. 이 layer는 9개의 units를 가지고 있고, 각각의 unit은 다음과 같은 범위의 x에 접근이 가능하다. 그리고 9개의 units을 가진 layer(first layer)의 output은 3개의 units을 가진 layer의 input 값으로 입력된다. 3 units의 layer (second layer)도 convolutional layer이기 때문에 각각의 unit이 a[1]의 결과 중 일부에만 접근이 가능하다. 그 다음 결과 값인 a[2]는 ouput layer에 입력되는데, 이 layer는 sigmoid 함수를 사용하는 layer이기 때문에 a[2]의 세가지 결과값을 모두 확인하고 사용할 수 있다. 그리고 나서 이 3가지 값으로 심장병의 존재 여부(binary classification)를 판단하여 결과를 낼 수 있다.
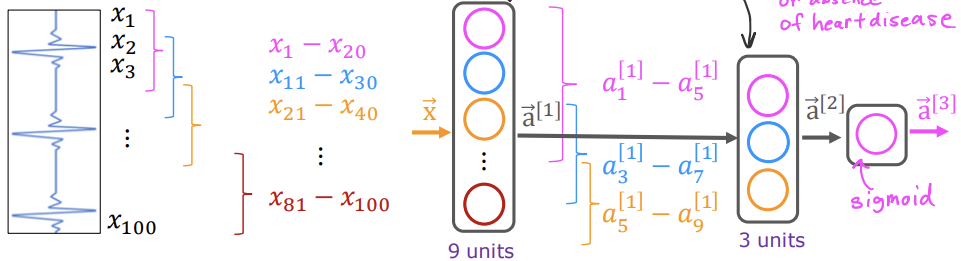
convolutional layer는 이러한 방식으로 작동되기 때문에 "각 unit이 볼 수 있는 input의 범위", "각 layer가 몇 개의 units을 가질지"를 결정해주어야 한다.



