
juuuding
[Advanced Learning Algorithms] Neural Networks - Neural Networks intuition 본문
[Advanced Learning Algorithms] Neural Networks - Neural Networks intuition
jiuuu 2023. 11. 16. 23:16Neurons and the brain
Neural networks란 뇌를 모방한 알고리즘이다. 인간의 뇌는 한 뉴런에서 다른 뉴런으로 신호를 보내며 생각이라는 것을 하게 되는데, 이러한 특징을 단순화하여 만든 모델이 Neural Networks이다.
Demand Prediction
예를 들어 소비자가 옷을 살지 안살지를 예측하는 모델을 살펴보자. 소비자의 구매 여부를 결정하는 요소는 cost, shipping cost, marketing, material로 정했다. 그리고 하나의 layer은 3개의 neurons(units)로 구성하였고, 이 unit들은 각각 affordability, awawreness, perceived quality 에 해당한다. 한 layer은 동일하거나 유사한 특징을 입력 받아 몇 개의 숫자를 함께 츨력하는 뉴런들을 그룹화 한 것이다. 밑에서 볼 수 있듯이 input layer들은 layer1에 모두 접근이 가능하다. 이 neural network를 거친 결과로는 소비자가 이 상품을 살 확률이 나타나며 이 수치는 "activation"이라고도 표현된다. "activation"은 한 layer을 거친 후 발생하는 결과를 이르고, 우리 뇌로 표현하자면 생물학적 뉴런이 높은 출력 값을 보내거나 다른 뉴런에 많은 전기 자극을 하류로 보내는 정도를 나타낸다.

만약 layer가 다음과 같이 여러개라면 multilayer perception이라고 한다. 신경망을 구축할 때 우리는 원하는 hidden layer 수, hidden layer에 포함할 뉴런수만 결정하면 된다. 그렇기 때문에 신경망은 데이터로부터 신경망을 훈련시킬 때 다른 기능이 무엇인지 명시적으로 결정할 필요가 없다는 것이 장점이다.
Example: Recognizing Images
[Face recognition]
이 사진 속 인물의 신원을 출력하는 신경망을 훈련해보자. 우선 1000 x 1000 face image를 1열로 펴서 벡터를 구성한다.
그리고 이 픽셀들의 밝기를 나타내는 특징 벡터를 hidden layer1에 공급하고 일부 특징을 추출한다. 추출된 특징은 hidden layer2에 공급되고 여기서 나온 특징은 hidden layer3으로 공급된다. 그러고 나면 마지막으로 output layer은 이 사람이 특정인일 확률을 추정한다.
많은 사진을 가지고 이 신경망을 훈련시키고 hidden layer에 있는 뉴런들을 보면 이들이 무엇을 계산하는지 알 수 있다. hidden layer1의 첫번째 뉴런은 수직선이나 이와(첫번째 네모 박스) 비슷한 수직 가장자리를 찾는다. 두번째 뉴런은 이와(두번째 네모 박스) 같은 방향이 있는 선이나 가장자리를 찾고, 세번째 뉴런은 해당 방향(세번째 네모 박스)의 선을 찾는다. 이것을 보면 hidden layer1에서는 뉴런이 image에서 매우 짧은 선이나 매우 짧은 가장자리를 찾는 것을 볼 수 있다.
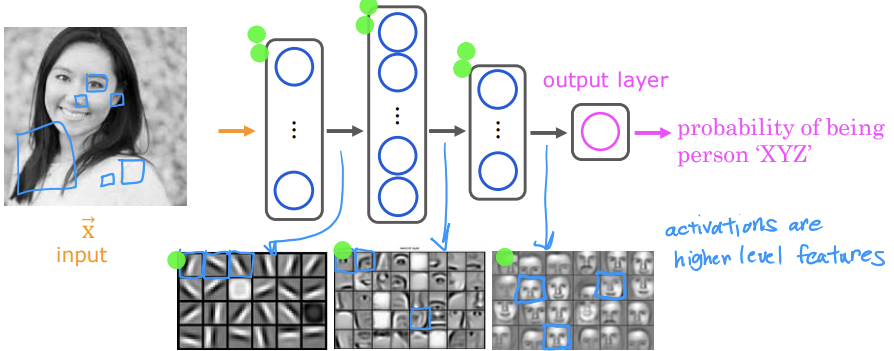
그 다음으로 hidden layer2를 살펴보면 많은 짧은 선과 작은 가장자리 부분을 그룹화하는 방법을 학습한다. 예를 들어 그림1의 작은 사각형들은 뉴런이 감지하려는 대상을 시각화한 것이다. 여기서 hidden layer2의 첫번째 뉴런은 image의 특정 위치에서 눈의 유무를 감지하려는 것이다. 두번째 뉴런은 코 끝을 감지하는 것처럼 보이고, 4행 5열의 뉴런은 귀 아래쪽을 감지하려는 것으로 보인다.
다음 hidden layer을 보면 이제 신경망이 얼굴의 여러 부분을 모아 더 크고 대략적인 얼굴 모양의 유무를 감지하려고 한다. 마지막으로 얼굴이 다른 얼굴 모양과 얼마나 일치하는지 감지하면 더 풍부한 feature들의 집합이 생성되고, 이를 통해 output layer가 인물 사진의 정체를 판단할 수 있는 수치를 출력한다.
신경망의 놀라운 점은 hidden layer에 있는 특징 탐지를 신경망이 스스로 학습한다는 것이다. 이 예제로 말하자면, 첫번째 레이어에서는 짧고 작은 가장자리, 두번째 레이어에서는 눈/코 같은 얼굴 부분, 세번째 레이어에서는 완전한 얼굴 모양을 찾으라고 신경망에게 말한 사람은 아무도 없다는 것이다.
여기서 주의할 점은 첫번째 레이어가 비교적 작은 창으로 가장자리를 찾고, 두번째 레이어는 더 큰 창을 보고, 세번째 레이어는 두번째보다 더 큰 창을 보고 있다는 것이다. 이것은 이미지에서 실제로 크기가 다른 영역에 해당한다.
이 동일한 신경망에 다른 데이터셋으로 훈련을 시킨다면 어떤 일이 발생할까?
[Car classification]
우선 위의 신경망에 자동차 사진 여러장, 옆면 사진으로 훈련을 시킨다. 동일한 학습 알고리즘으로 자동차를 탐지하도록 요청하면 hidden layer1은 경계선을 학습한다. 그리고 hidden layer2는 바퀴, 문과 같은 자동차 부품을 감지하고 hidden layer3에서 더 완전한 자동차 형태를 감지하는 방법을 배운다.
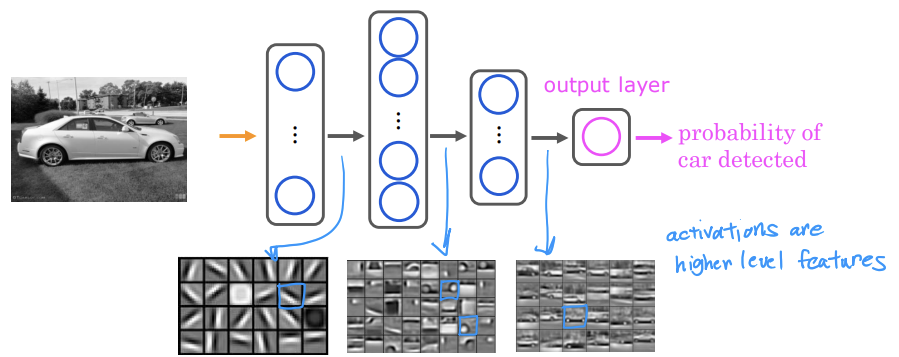
이처럼 신경망은 서로 다른 데이터를 입력하는 것만으로도 아주 다른 특징을 감지하는 방법을 자동으로 학습하여 자동차 감지, 사람 인식 등과 같은 특정 과제에 대한 훈련 대상 여부를 예측한다. 이것이 컴퓨터 비전 애플리케이션에서 신경망이 작동하는 방식이다.



