
juuuding
[Supervised Machine Learning: Regression and Classification] Classification with Logistic regression 본문
[Supervised Machine Learning: Regression and Classification] Classification with Logistic regression
jiuuu 2023. 10. 24. 13:40출력 변수 y가 숫자 범위에 있는 값 대신 가능한 몇가지 값 중 하나만 가질 수 있는 "Classification"에 대해 알아볼 것이다. 결론부터 말하면 linear regression은 classification 문제에 적합한 알고리즘이 아니며, classification에는 "logistic regression"을 이용한다.
Classification
출력 값 y가 오직 두 값 중 하나만 될 수 있을 때 이것을 "binary classification"이라고 한다. 이 binary classification은 0 or 1의 결과 값을 가진다고 표현될 수 있으며, 0은 false(negative), 1은 true(positive)의 의미를 나타낸다. 여기서 negative, positive는 나쁘고 좋은 것이 아니고, 부재와 존재를 나타내는 의미이다.
[Motivations]
이제 왜 classification에는 linear regression이 부적합한지에 대해 알아보자. 아래의 그림1은 tumor size에 따라 tumor이 malignant인지 아닌지를 그린 것이다.

이 그림1에 맞는 linear regression을 그리면, 다음과 같은 그래프가 그려진다.

위의 그래프를 바탕으로 종양이 악성인지 아닌지 구분하기 위해 threshold을 0.5로 설정하고, 이 지점을 0 / 1의 구분점으로 사용한다. 그렇게 했을 때, 위의 데이터들은 해당 분류에 모두 잘 만족하는 모습을 보인다. 여기까지 보면 liner regression도 classification에 적합한 것으로 보인다.
하지만 여기서 종양 사이즈가 기존의 악성 종양 사이즈보다 훨씬 큰 데이터 값을 넣은 후, 이에 맞게 갱신된 linear regression을 그리면 아래와 같은 그림이 그려진다.

이때 데이터들을 threshold에 의한 0 / 1을 구분하는 지점으로 악성인지 아닌지를 판별하면 악성 종양 중 가장 작은 두 종양은 악성이 아닌 것으로 분류가 된다. 이와 같은 이유로 linear regression은 classification에 적합한지 않으며 앞으로 classification에는 "logistic regression"을 사용할 것이다.
여기서 logistic regression에 regression이라는 단어가 들어가 있음에도, 실제로는 classification에 사용된다는 것을 주의해야한다.
[Logistic Regression]
logistic regression이란 아래의 그림과 같이 데이터에 s자형 곡선을 맞추는 것이다.

이 그래프에서 가로축을 z로 바꾸고 세로축을 g(z)로 하여 다시 그래프를 그리면 다음과 같다.

이 그래프를 "sigmoid function", "logistic function"이라고 한다. 결과 값 g(z)는 0과 1 사이의 값이여야 하며, 이 값은 g(z)가 1일 확률을 뜻한다. 여기서 z와 g(z)는 아래와 같이 표현된다.

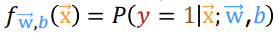
* 처음에 f_w,b(x) = g(z) = g(wx+b)라고 해서 헷갈렸다. f_w,b(x)는 linear regression wx+b인데 이 식이 어떻게 같은 거지?라고 생각했었다. 그런데 f_w,b는 linear regression을 특정 짓는 말이 아니라 일반적인 regression을 통용적으로 이르는 말인 것 같다... 그냥 단순하게 이 logistic regression에서는 f_w,b(x)가 g(z)라고 생각하면 될 듯하다.
[Decision Boundary]
2개의 특징이 있는 분류 문제 (binary classification)에서, y의 값이 0인지 1인지 결정할 수 있는 경계인 로지스틱 회귀의 결정 경계에 대해 알아보자.

위의 그림에서 g(z)가 0.5보다 크면, 즉 z가 0보다 크면(wx+b ≥ 0) y의 값은 1이고 반대의 경우 y의 값은 0이다. 0.5와 같이 이렇게 y의 레이블을 결정할 수 있는 경계를 "Decision boundary"라고 한다.
앞서 보던 것과는 다르게 feature이 2개인 경우를 살펴보겠다. 이런 경우라면 f_w,b(x)가 즉 g(z)가 다음과 같은 식으로 구성된다.

위의 식에서 w1을 1, w2를 1 b를 3으로 가정하고, 데이터를 바탕으로 한 그래프를 그려보면
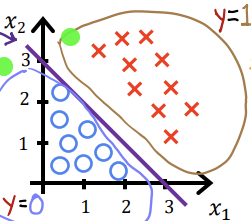
이런 그림이 나온다. 위에서 z=0일 때 결정 경계를 생성했던 원리를 적용하여, 여기서도 z인 w1x1+w2x2+b가 0일 때를 결정 경계로 설정하면 보라색 선이 이 데이터 값들의 결정 경계가 된다 (x1+x2+3 = 0) . 따라서 x1+x2+3 ≥ 0이면 label이 1이되고, 그 반대면 label이 0이 되는 것이다.
이번에는 non-linear decision boundary가 되는 경우를 알아보자. feature engineering을 하여 x의 값들을 거듭 제곱으로 만들어 주면 다음과 같이 원형 decision boundary가 생성된다.

feature을 2개보다 더 많은 값으로 늘려준다면 다음과 같이 다양한 모양의 decision boundary가 생성될 수 있다.


여기서 결론은 decision boundary의 모양은 꼭 linear 하지 않아도 된다는 것이다. feature 값에 따라 다양한 모양의 decision boundary가 생성될 수 있다.



